Missing Domain Information Knime
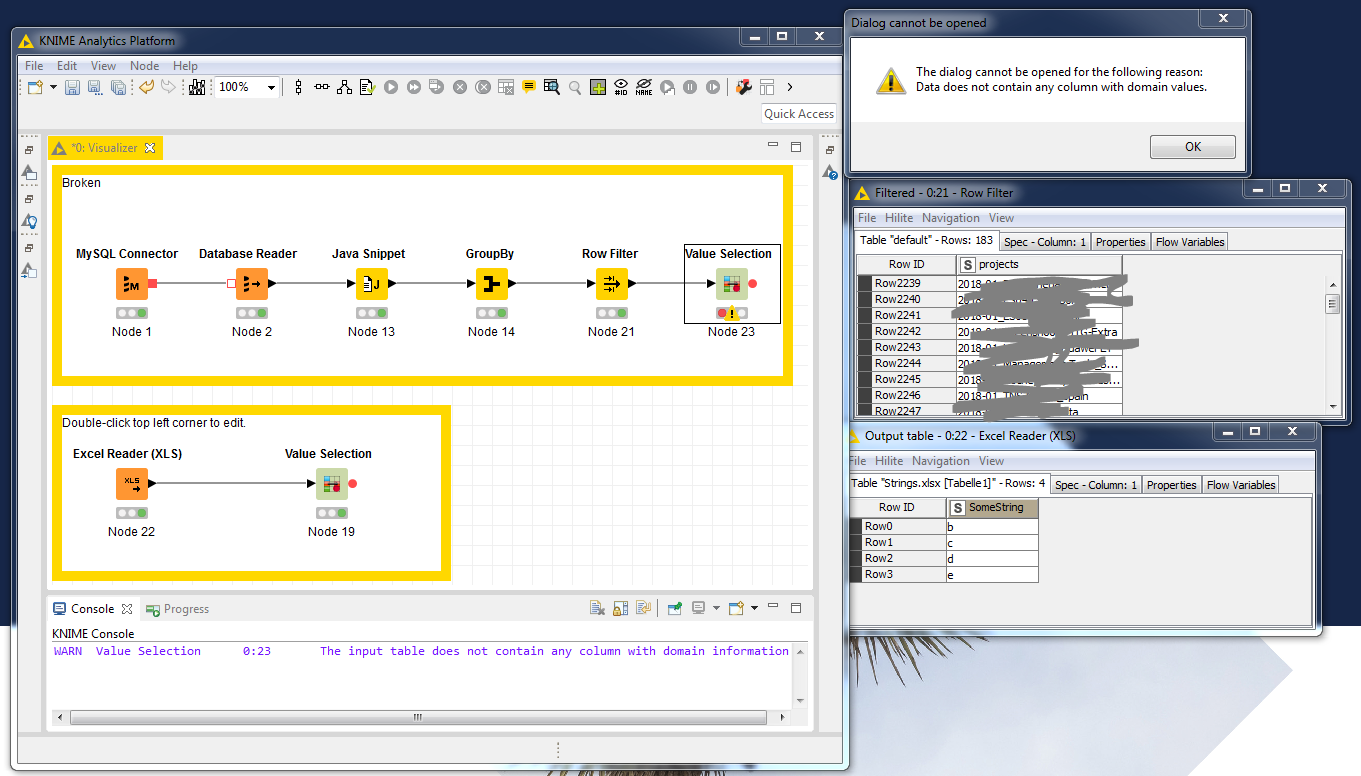
Value Selection Node Error The Input Table Does Not Contain Any Column With Domain Information Knime Analytics Platform Knime Community Forum
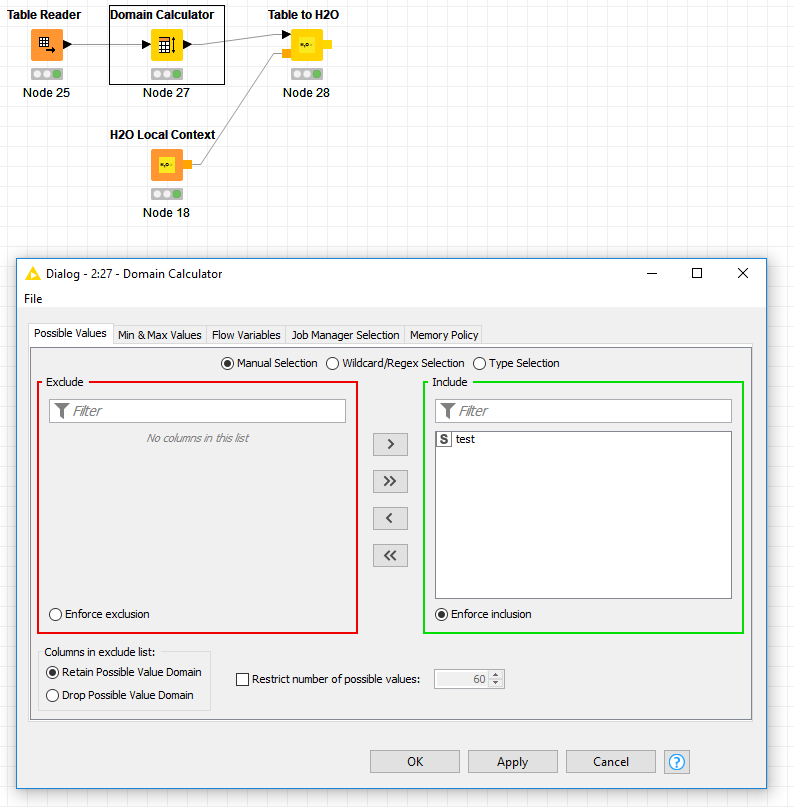
Bug H2o Table To Frame Knime Analytics Platform Knime Community Forum
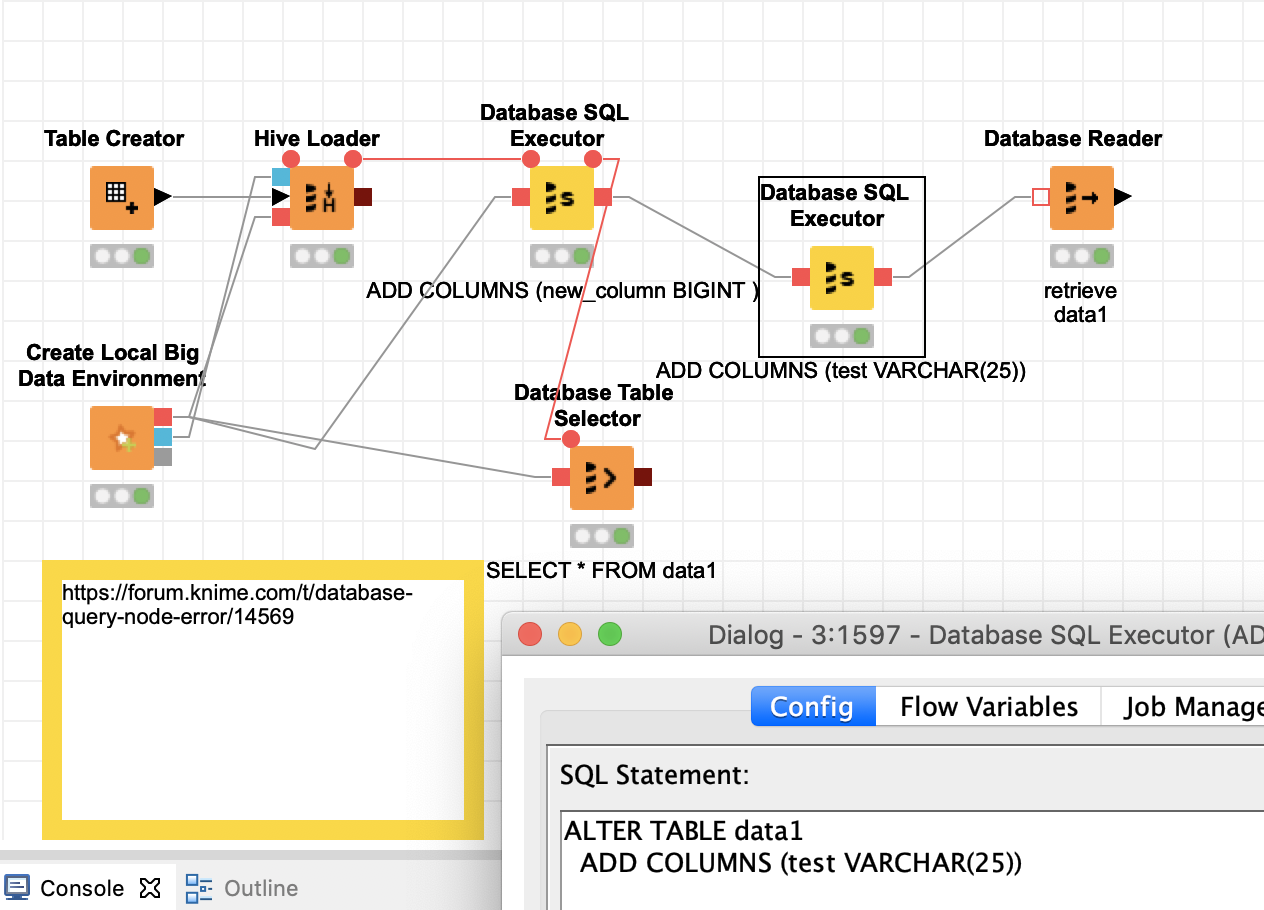
Database Query Node Error Knime Analytics Platform Knime Community Forum
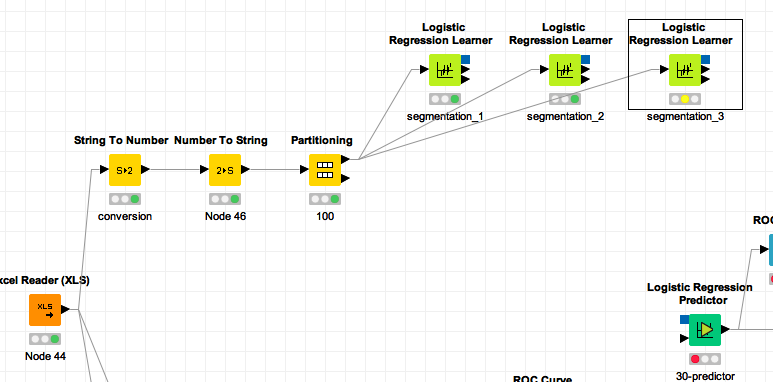
Logistic Regression Learner Node Won T Execute Knime Analytics Platform Knime Community Forum
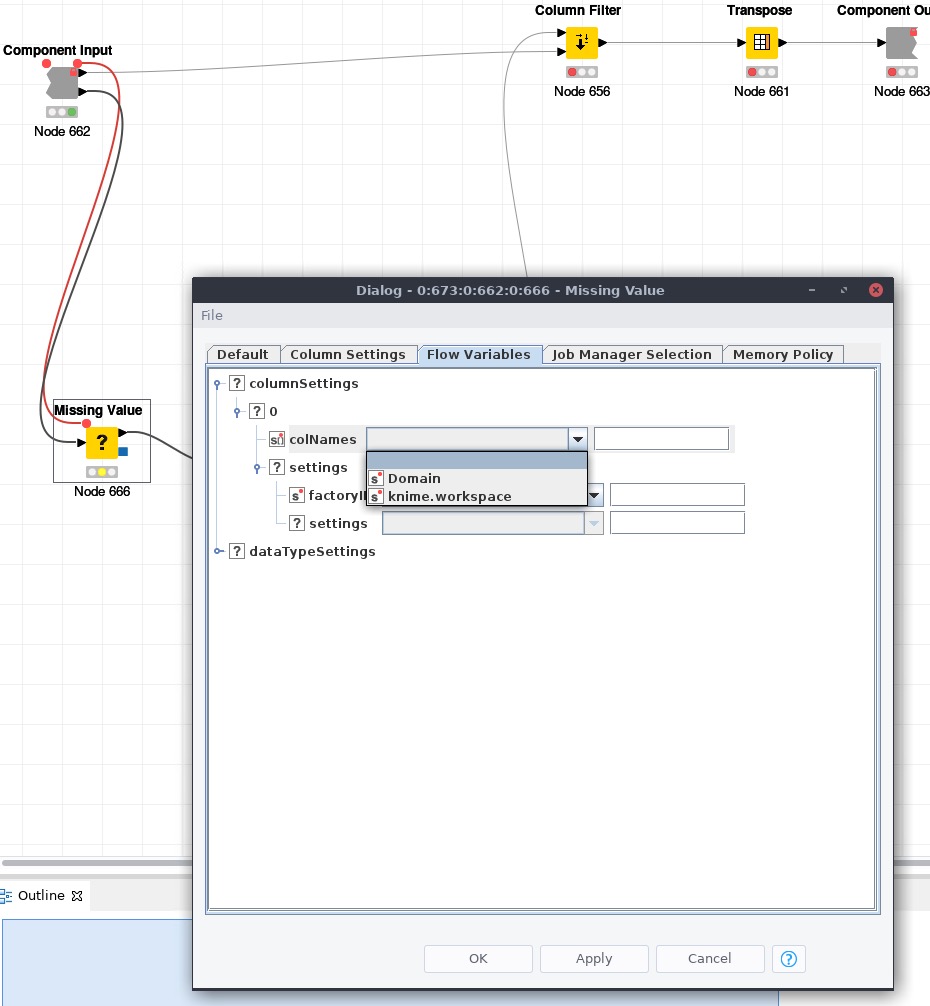
Bug Flow Variable Not Available In Component Nodes Knime Analytics Platform Knime Community Forum
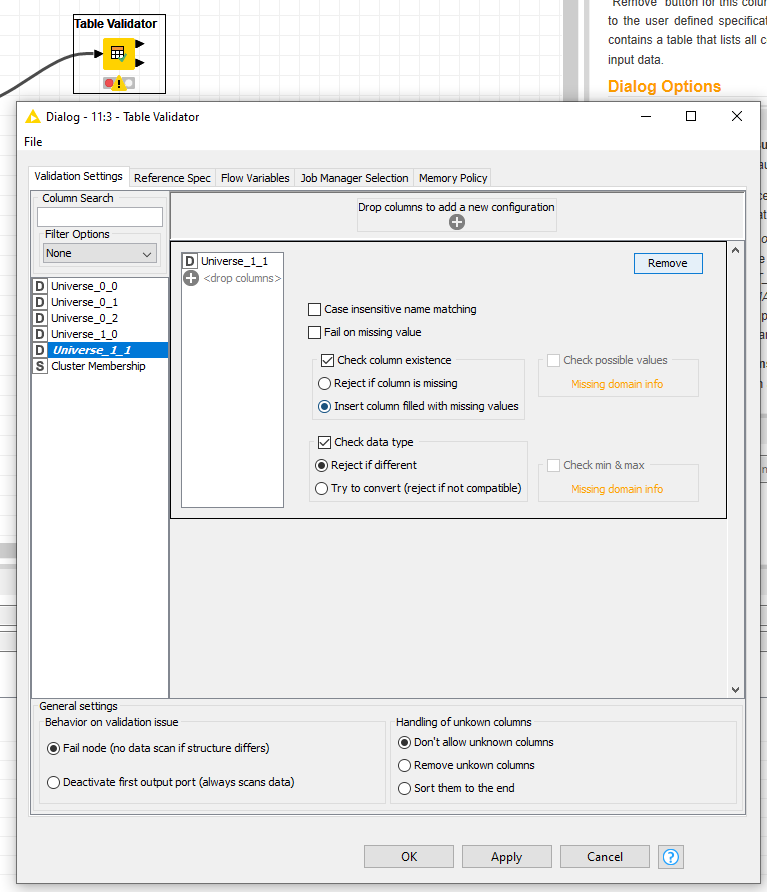
Add Column If Doesn T Exist Knime Analytics Platform Knime Community Forum
Put data science into production in the enterprise with knime server.
Missing domain information knime. This can improve performance. The default value is set to the number of processors or cores that are available to knime. To do this a data scientist creates a knime workflow that extracts terms and properties from a certain ontology and applies this knowledge to different tasks ranging from domain exploration to data integration.
If set to 1 the algorithm is performed sequentially. This node is useful when the domain information of the data has changed and must be updated in the table specification for instance the domain information as contained in a table spec may be void when a row filtering e g. Skip nominal columns without domain information if checked nominal columns containing no domain value information are skipped.
Resorts and or inserts interactively possible values to the domain of a certain column of the input table. Scans the data and updates the possible values list and or the min and max values of selected columns. The free and open source visual workflow builder.
Domain calculator 4 parameter optimization loop. Outlier removal is carried out. A histogram that should show an empty bin for a value that is not actually present in the data.
Also the sorting on the domain values can be changed. Learns a random forest which consists of a chosen number of decision trees. Scans the data and updates the possible values list and or the min and max values of selected columns.
To use this node in knime install knime ensemble learning wrappers from the following. Each of the decision tree models is learned on a different set of rows records and a different set of columns describing attributes whereby the latter can also be a bit vector or byte vector descriptor e g. The reading and processing of ontologies can be automated with knime analytics platform.
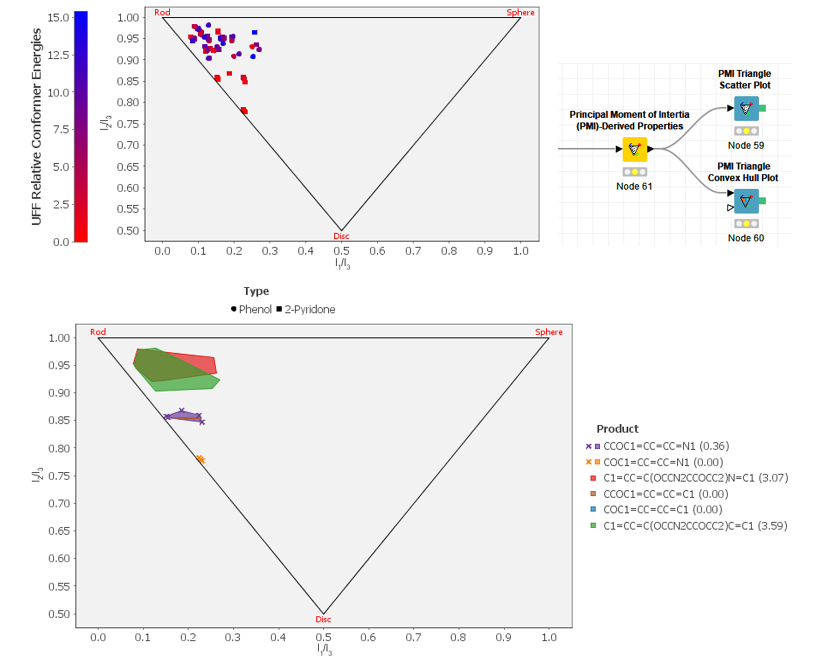
Update To V1 22 0 New Pmi Nodes Vernalis Knime Community Forum
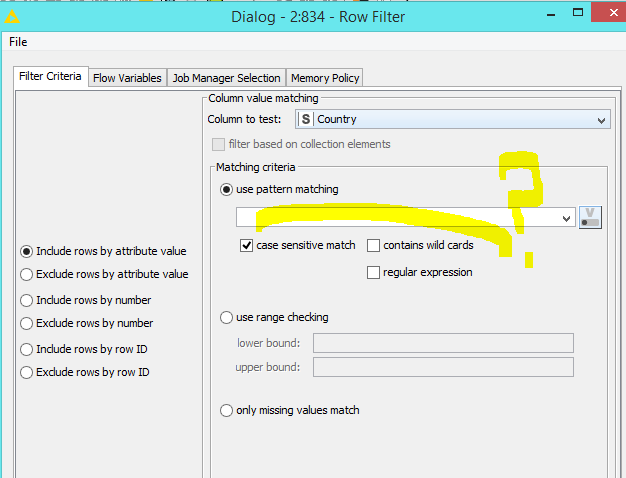
Why Can T I See The List To Filter Row Filter Knime Analytics Platform Knime Community Forum
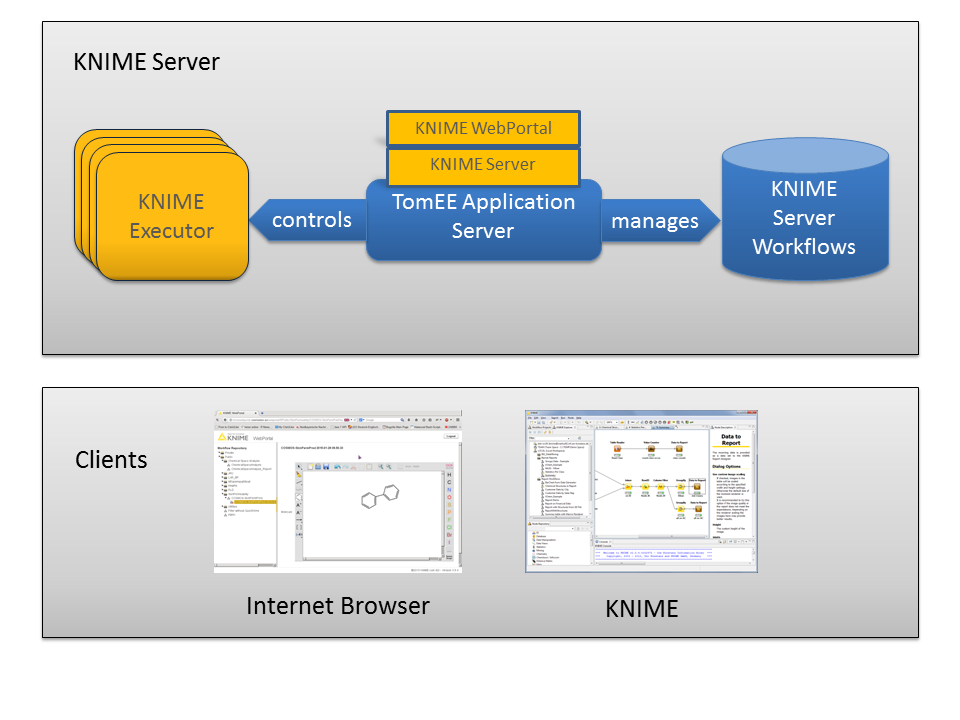
Knime Server Administration Guide
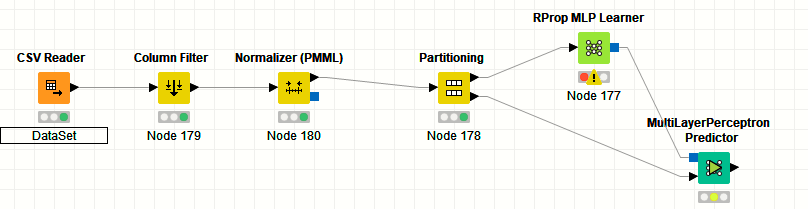
How To Optimize The Two Variable S Values In Linear Regression Knime Analytics Platform Knime Community Forum
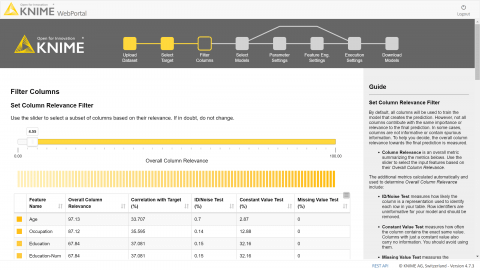
Business Leader Knime
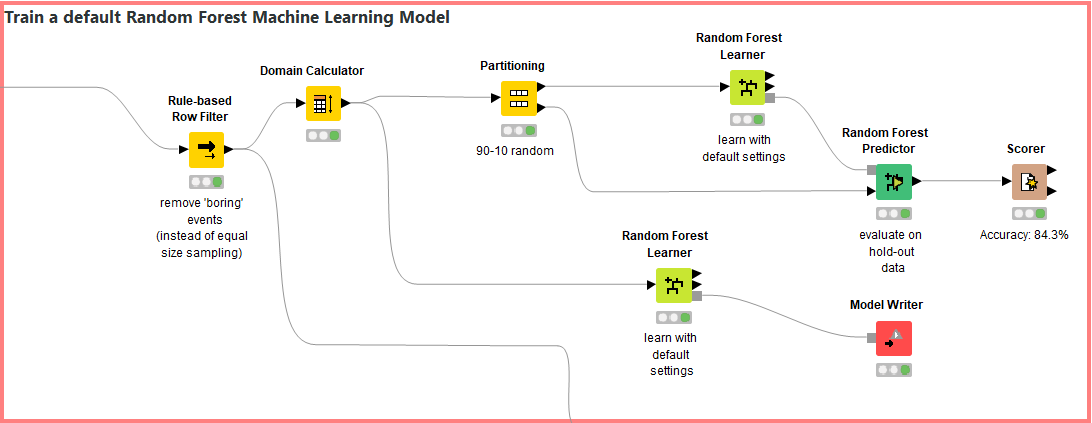
Cumulocity Iot And Knime Analytics Platform Knime

Knime 4 0 1 Crashes Knime Analytics Platform Knime Community Forum
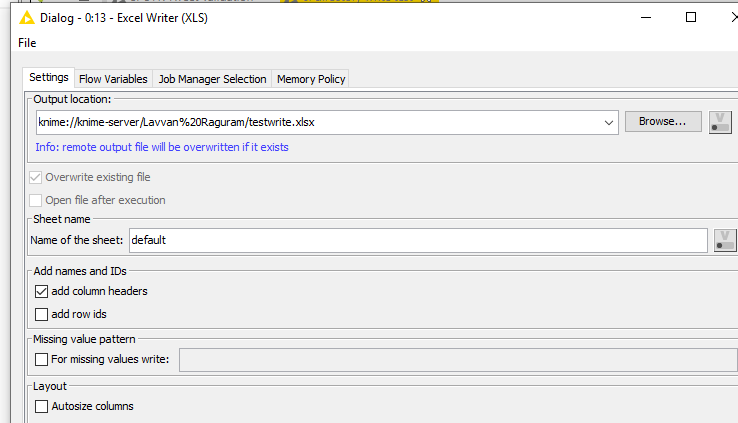
Knime Server To Save Excel File On Shared Network Drive Knime Server Knime Community Forum
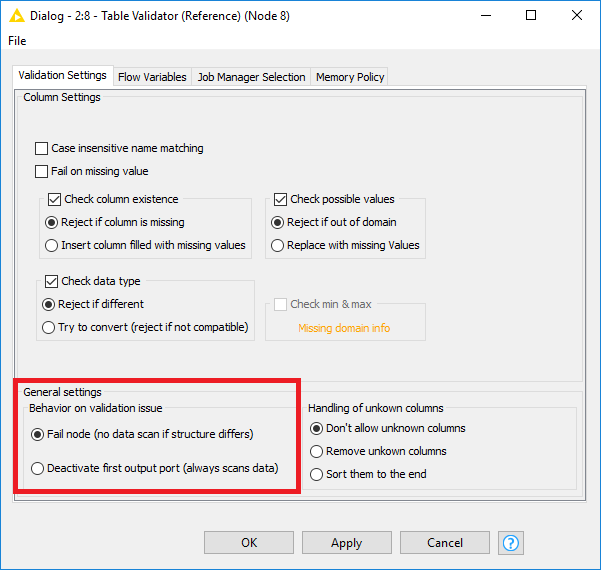
Table Validator Reference Feature Request Knime Analytics Platform Knime Community Forum
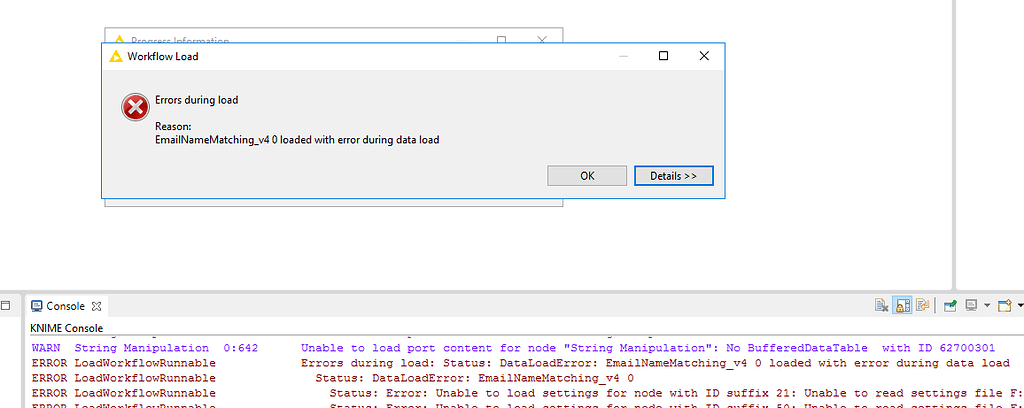
Serious Bug Error When Opening A Workflow Nodes Corrupted Missing Knime Analytics Platform Knime Community Forum
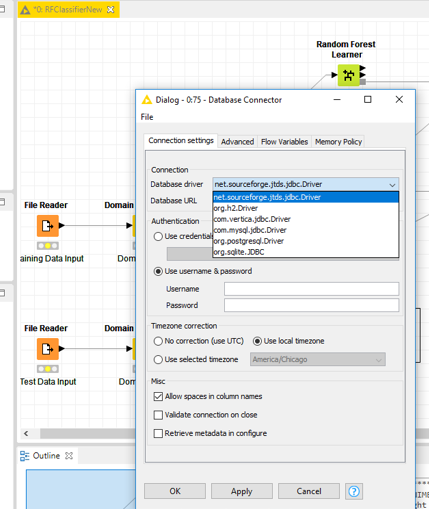
Sap Hana Connection Knime Knime Analytics Platform Knime Community Forum

Why Knime By Rosaria Silipo By Rosaria Silipo The Startup Medium
Domain Calculator Nodepit