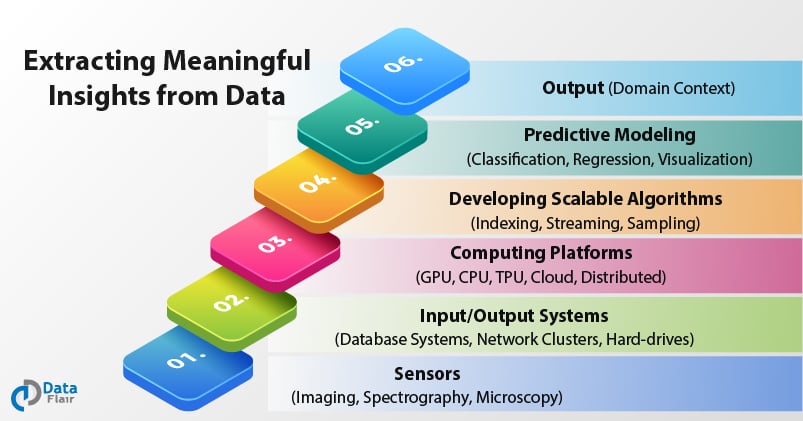
Domain Information Extraction
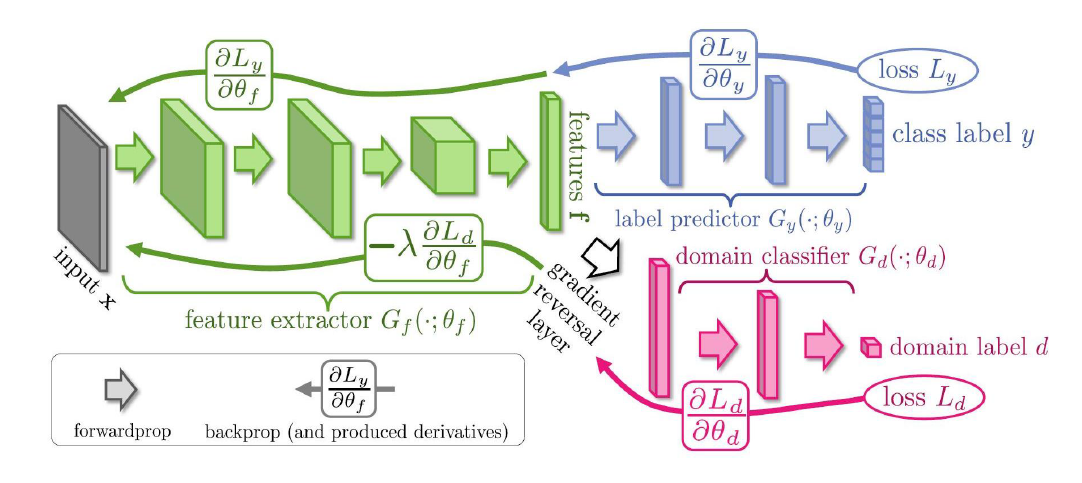
Deep Domain Adaptation In Computer Vision By Branislav Hollander Towards Data Science

Towards Automatic Summarization Part 2 Abstractive Methods Topic Sentences Sentence Correction Nlp Techniques

Information Extraction What Is Text Analysis Ontotext Text Analysis Semantic Technology Text Analysis Analysis Text

Spatial Domain An Overview Sciencedirect Topics
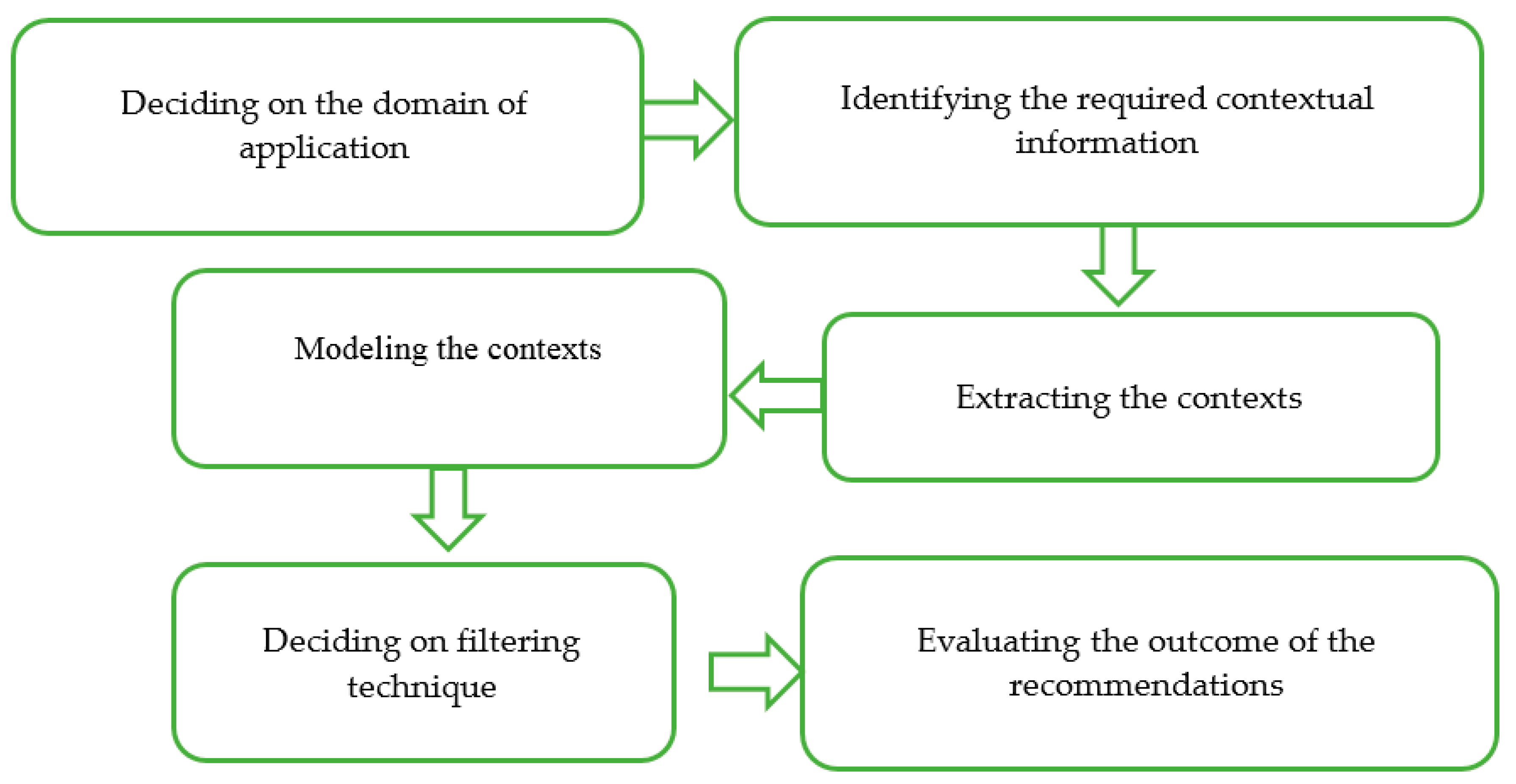
Applied Sciences Free Full Text Context Aware Recommender System A Review Of Recent Developmental Process And Future Research Direction Html
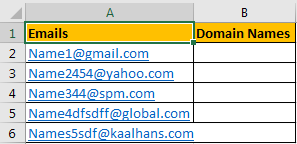
How To Extract Domain Name From Email In Excel

This paper introduces a system to extract entity relations from indonesian text in triple format using an nlp pipeline rule based candidates generator rule based token expander and machine.
Domain information extraction. The system relies on a series of natural language processing methods including coreference resolution and open domain information extraction in which the subject predicate and object are natural language phrases extracted from the sentences within the top k documents as discussed above. Information extraction is the part of a greater puzzle which deals with the problem of devising automatic methods for text management beyond its transmission storage and display. We rely on a series of natural language processing methods including open domain information extraction a special filtering method to maintain only meaningful relationships and a heuristic to form graphs with a high coverage rate of topic entities and concepts.
Traditionally these are extracted using a large set of patterns. Our graph visualization then allows users to explore these connections. Using information extraction we can retrieve pre defined information such as the name of a person location of an organization or identify a relation between entities and save this information in a structured format such as a database.
Preprocessor named entity recognizer. Vieira2 and ricardo r. This paper aims at automatic pattern extraction from web for the task of domain specific information extraction.
Ciferri1 1 department of computer science federal university of são carlos são carlos sp brazil 2 faculty of mathematical and nature sciences methodist university. Information extraction for decision support systems pablo f. Unfortunately open domain information extraction open ie systems are language specific and there is no published system for indonesian language.
However this approach is brittle on out of domain text and long range dependencies and gives no insight into the substructure of the arguments. Relation triples produced by open domain information extraction open ie systems are useful for question answering inference and other ie tasks. Methods for domain independent information extraction from the web.
The discipline of information retrieval ir 1 has developed automatic methods typically of a statistical flavor for indexing large document collections and classifying documents. An environment for data analysis in biomedical domain. In fact we need to be able to operate open domain ie in which the domain of interest results from several interactions with the user in quest of capturing novel data trends from massive hlt 02 san diego california usa.
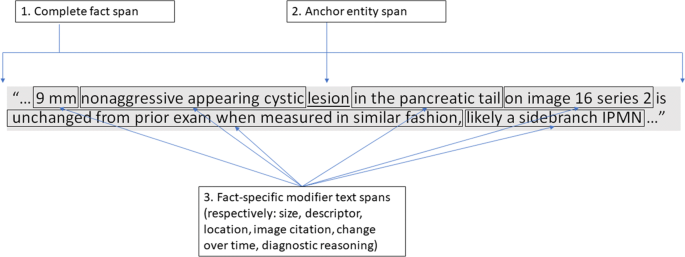
Toward Complete Structured Information Extraction From Radiology Reports Using Machine Learning Springerlink

Keyword Extraction A Guide To Finding Keywords In Text
Relation Extraction Papers With Code

How To See What S Behind A Website The Kit 1 0 Documentation

Introduction To Information Extraction Using Python And Spacy Data Science Python Computational Linguistics
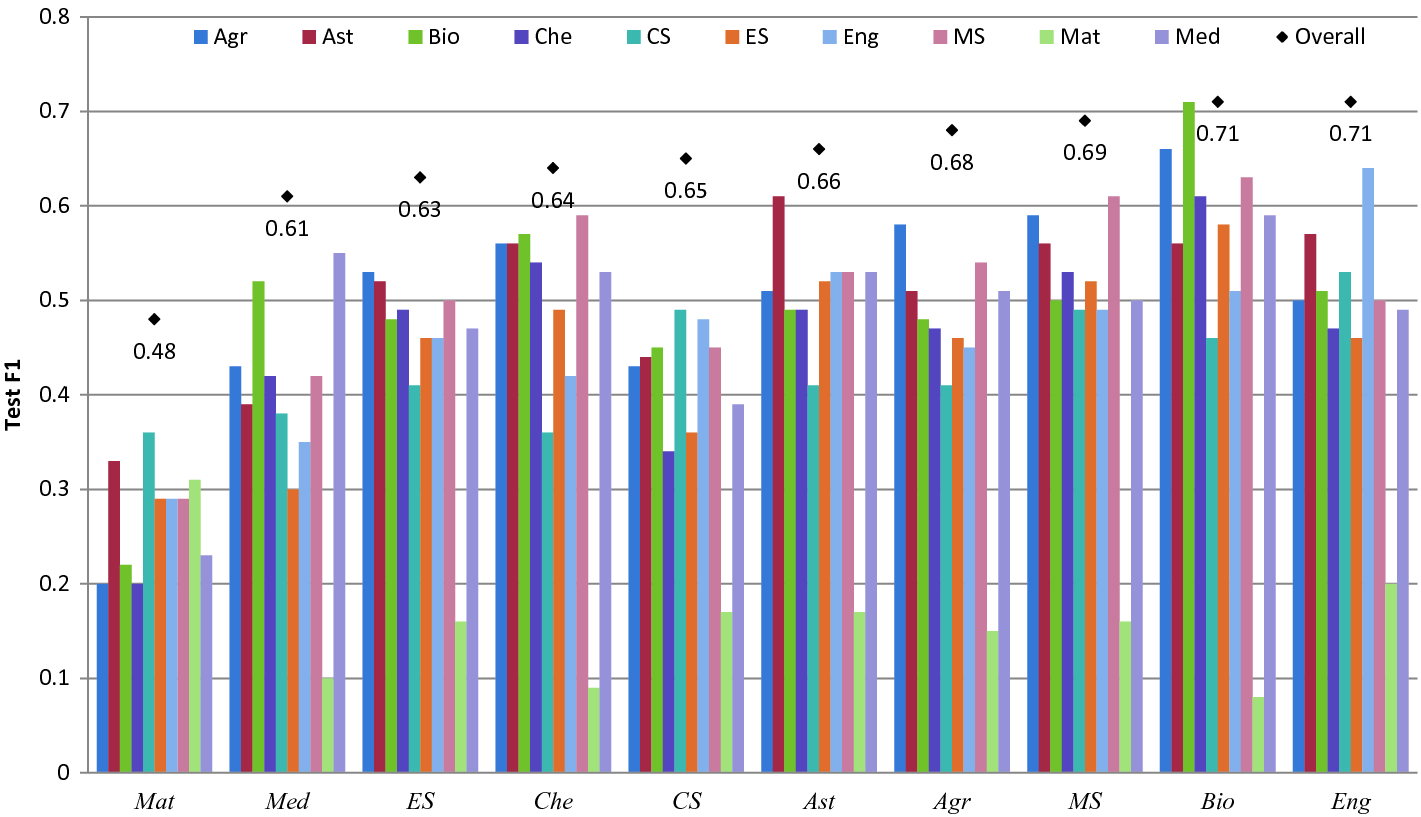
Domain Independent Extraction Of Scientific Concepts From Research Articles Springerlink

Relation Extraction Using Distant Supervision A Survey
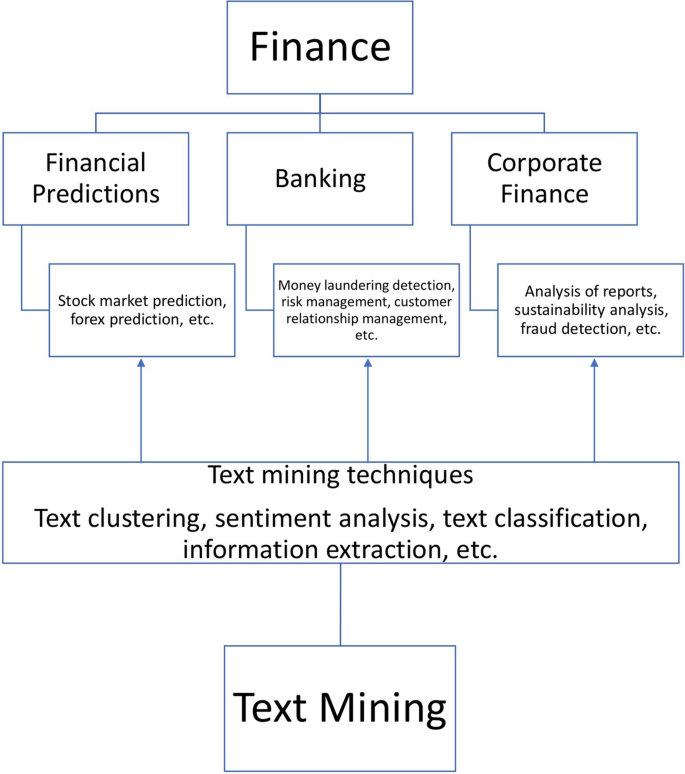
Comprehensive Review Of Text Mining Applications In Finance Financial Innovation Full Text

Chapter 4 Domain Driven Analysis Of Architecture Reconstruction Methods Model Management And Analytics For Large Sc Management Online Learning Live Training
Simple Automatic Feature Engineering Using Featuretools In Python For Classification Feature Extraction Domain Knowledge Engineering

Content Based Recommender Using Natural Language Processing Nlp Kdnuggets Nlp Natural Language Language

Semeval 2018 Task 7 Semantic Relation Extraction And Classification In Scientific Papers Acl Anthology